


Improve Lead Time By Removing Uncertainty
Improve Lead Time By Removing Uncertainty
Lead Time is heavily affected by uncertainty. The more uncertainty, the longer the Lead Time.

Lead Time
Lead Time is the time between when a feature starts and when it’s deployed to production. It’s a standard performance metric for software development. It measures all the processes in the software development cycle, from requirements gathering to testing.
Lead Time is heavily affected by uncertainty. The more uncertainty, the longer the Lead Time.
Simulation
To demonstrate the influence of uncertainty quantitatively, I created a simulation (well, Chat GPT did) of a process and ran it many times with different parameters.
Simulation: Known Duration
I created a process that has four steps:
Step 1: Takes 3 days.
Step 2: Takes 4 days.
Step 3: Takes 5 days.
Step 4: Takes 3 days.
If we send a task to this process, it takes 15 days to complete (3 + 4 + 5 + 3 = 15). This is the Lead Time in this case.
Assuming that each step can work one task at a time, if I send a new task only one day after the first one it will stay waiting for the next task to finish that step.
I plotted what would happen to the lead time if there was a new task every 4, 5, and 6 days:

The Lead Time increases when there is a new task every four days because they get stuck before Step 3, which needs five days to complete.
Yet, the Lead Time stays constant at fifteen days when a new task is added every five or six days.
Simulation: Duration With Variance
Let’s now add some variance to the steps:
Step 1: Takes 2, 3, or 4 days.
Step 2: Takes 3, 4, or 5 days.
Step 3: Takes 4, 5, or 6 days.
Step 4: Takes 2, 3, or 4 days.
I kept the average of each duration the same as before. Each duration has the same probability of being chosen. For example, a task might spend two days in Step 1, five days in Step 2, five days in Step 3, and two days in Step 5.
In the previous scenario, the Lead Time was always fifteen when a new task was added every five days. Is it still the case with the variance?
I ran the simulation 1000 times with those parameters and then plotted the average of Lead Times.
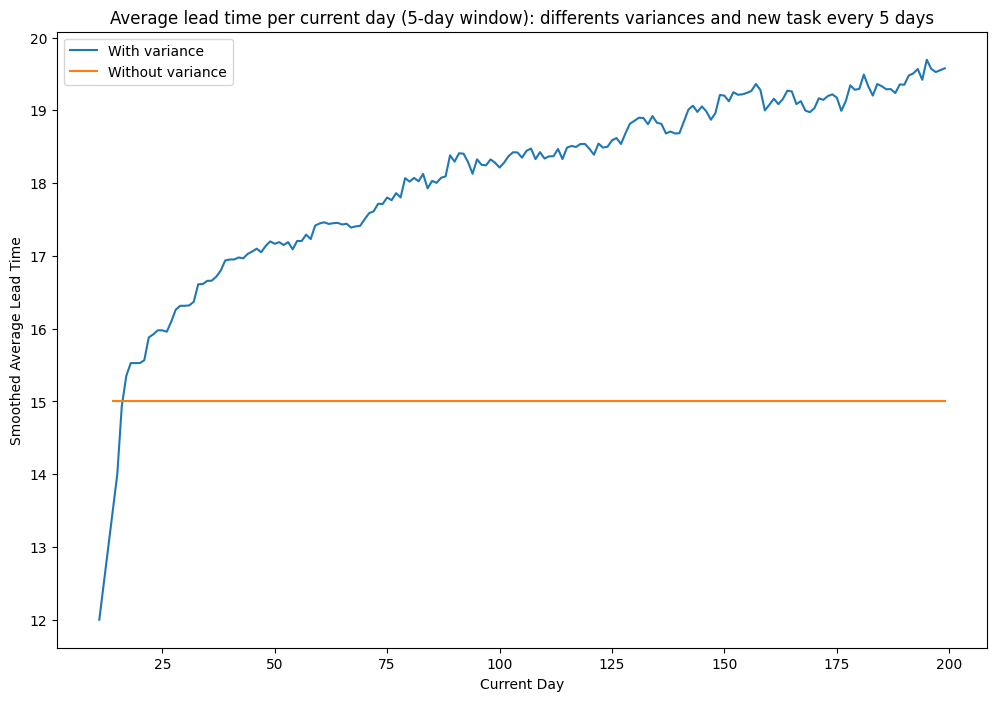
The sum of the averages is not the same as the Lead Time.
The reason is in Step 3. This step might take six days, which is higher than the frequency of new tasks (five days). Therefore, some tasks might get stuck in it waiting in Step 2.
Simulation: Even More Variance
Let’s add even more variance. We keep the average the same but add one day variance for each per step:
Step 1: Takes 1, 2, 3, 4, or 5 days.
Step 2: Takes 2, 3, 4, 5, or 6 days.
Step 3: Takes 3, 4, 5, 6, or 7 days.
Step 4: Takes 1, 2, 3, 4, or 5 days.
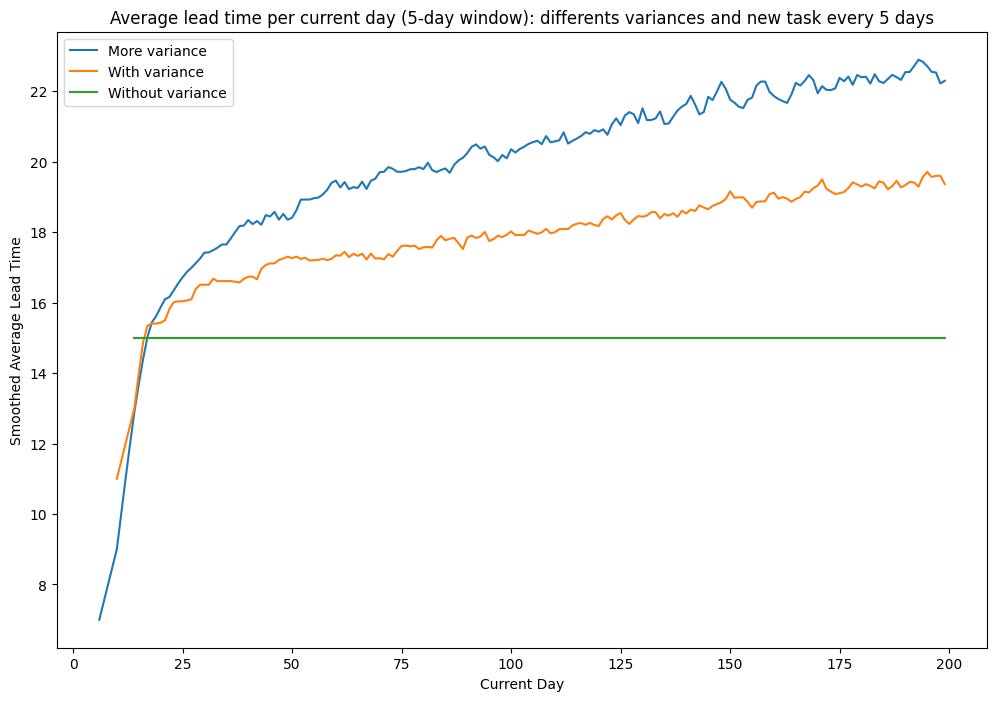
With more variance, the Lead Time average is even longer. That’s because Step 2 could also be a bottleneck when the task stays six days, and Step 3 is an even worse bottleneck with a duration of up to seven days.
Learnings
Learnings from the simulation:
If we add variance, the average lead time is not the sum of duration averages.
The more variance, the higher the lead time.
The maximum duration of a step affects the Lead Time, not the average.
Manage Uncertainty
Based on the simulation, we can draw a main (theoretical) conclusion about managing lead time: “Manage Uncertainty.”
Variance in duration comes from the uncertainty of the task—the more uncertain a task, the higher the variance.
How to reduce uncertainty will be a whole article. But I’d like to give some examples to help understand what I mean by managing uncertainty:
Define non-functional requirements like performance, scalability, and reliability.
For example, specify that a list component needs to support hundreds of thousands of items or just tens.
Reduce the size of the tasks.
For example, create MVP of features.
Find and resolve open questions before starting the work.
Have a feature launch meeting with stakeholders and open communication.
Do post-mortems on tasks that exceed the expected duration.
This helps in learning how to improve tasks in the future.
Thanks to Elina and Sebastià for reviewing this article!
Let’s start the conversation. How do you reduce uncertainty in your feature development?
I’d appreciate it if you shared this article if you found it interesting!
Love it. Regarding:
> • Find and resolve open questions before starting the work.
Touching, not solving just touching, on open questions sometimes exposes a fountain of business context that was hidden, so doing that early I, personally, find helpful in the understanding & exploring phase of a project.
But resolve all open questions before starting? What does resolve mean? We don't have perfect knowledge of the future and, just like generative AI, we are quite capable of imagining arms growing where there are actually legs, or boogiemen that don't exist at all, and the only effective solution to that is to get closer to key points. Expecting to have answers to every question from afar is like turning up the realism dial in generative AI; it will make textures more realistic but it will still put limbs in the wrong places. If "resolve" means deciding whether the question is important or not, and if important then making sure that we are close enough to it to understand and decide it then, yes, I agree. There is nothing as useful to clarifying a dream as jumping in to the darkest parts, without inhibitions or prejudice, for a very short time, just enough to get a taste. Maybe you will find out that the boogieman is not real. The quickest way of understanding the future can be to step into it. And let's not spend a huge amount of time planning solutions to questions that are likely to be details; like Mein Herr making a map to a scale of 1:1 only to find that the world itself is a better map than the hyper-detailed map and so giving up on map making altogether. Time spent planning is also time. Better: Agree with the customer whether questions are important for the MVP, which are details and which can be ignored altogether.
I, personally, like to separate exploration from trying to decide whether questions are important. I am not good at exploring and filtering at the same time. When exploring my mind is open, excitable and absorbs all kinds of stimuli, in the filtering stage it is cooler, more closed, more judgemental, and far less efficient at absorbing information.
Bib:
- Mein Herr on map making: https://people.duke.edu/~ng46/topics/lewis-carroll.htm